

Suchir Balaji, ex investigador y denunciante de OpenAI, fue encontrado muerto en su apartamento de San Francisco el pasado 26 de noviembre. El fallecimiento de Suchir Balaji se produce un mes después de haber escrito un artículo en el que cuestiona el uso de los datos protegidos por derechos de autor por parte de OpenAI. Balaji trabajó durante 3 años y 10 meses en la citada compañía. Según su perfil de Linkedin, Suchir entró en el año 2020 y se fue de la compañía en agosto de 2024.
Suchir Balaji publicó su artículo el 23 de octubre de 2024:
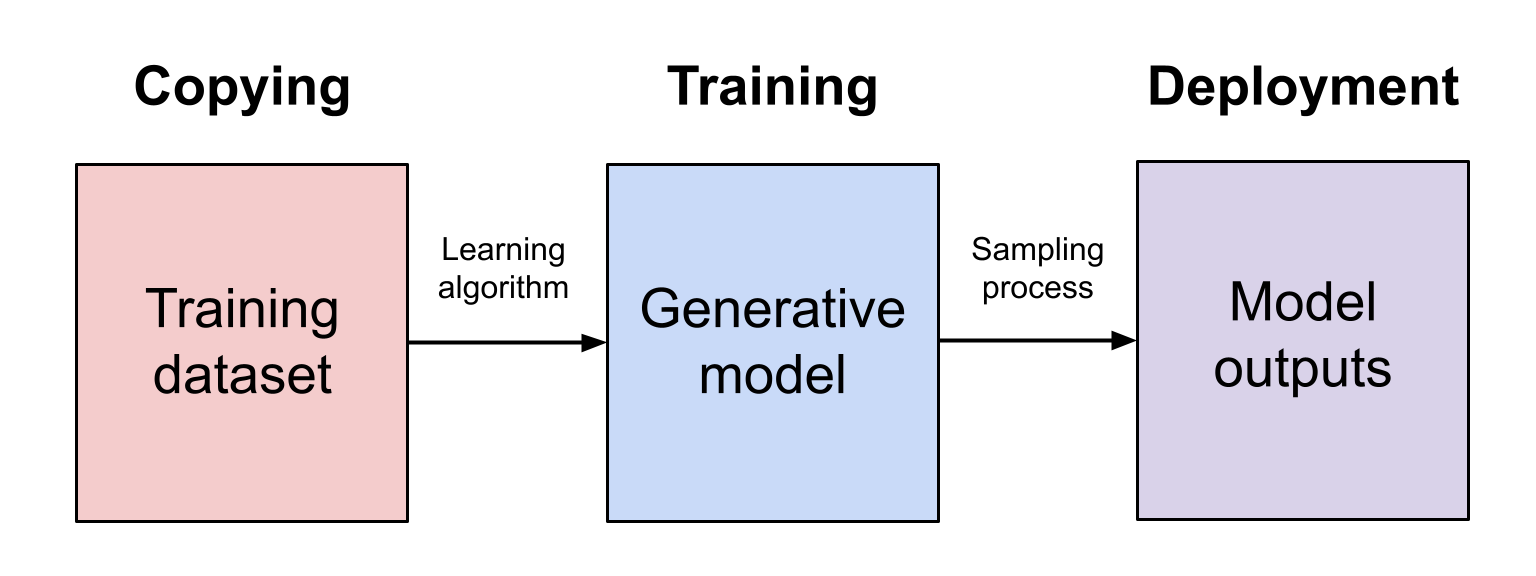
Si bien los modelos generativos rara vez producen resultados que sean sustancialmente similares a cualquiera de sus entradas de entrenamiento, el proceso de entrenamiento de un modelo generativo implica hacer copias de datos protegidos por derechos de autor. Si estas copias no están autorizadas, esto podría considerarse una infracción de los derechos de autor, dependiendo de si el uso específico del modelo califica o no como «uso justo». Debido a que el uso justo se determina caso por caso, no se puede hacer una declaración general sobre cuándo la IA generativa califica para un uso justo. En cambio, proporcionaré un análisis específico para el uso de ChatGPT de sus datos de entrenamiento, pero la misma plantilla básica también se aplicará a muchos otros productos de IA generativa.
Un ejército de agentes de IA se instala en nuestras vidas
ChatGPT, según Suchir Balaji
El uso justo se define en la Sección 107 de la Ley de Derechos de Autor de 1976, que citaré textualmente a continuación: No obstante lo dispuesto en los artículos 106 y 106A, el uso legítimo de una obra protegida por derechos de autor, incluido dicho uso mediante reproducción en copias o fonogramas o por cualquier otro medio especificado en dicho artículo, con fines tales como la crítica, el comentario, la información periodística, la enseñanza (incluidas varias copias para uso en el aula), la investigación o la beca, no constituye una infracción de los derechos de autor. Para determinar si el uso que se hace de una obra en un caso particular es un uso legítimo, los factores que se deben considerar incluyen:
- el propósito y el carácter del uso, incluyendo si dicho uso es de naturaleza comercial o para fines educativos sin fines de lucro;
- la naturaleza de la obra protegida por derechos de autor;
- la cantidad y la sustancialidad de la parte utilizada en relación con la obra protegida por derechos de autor en su conjunto; y
- el efecto del uso sobre el mercado potencial o el valor de la obra protegida por derechos de autor.
El uso legítimo
El hecho de que una obra no haya sido publicada no impedirá en sí mismo que se determine que existe un uso justo si tal determinación se realiza teniendo en cuenta todos los factores antes mencionados.
El uso legítimo es una prueba de equilibrio que requiere sopesar los cuatro factores. En la práctica, los factores (4) y (1) tienden a ser los más importantes, por lo que los analizaré primero. El factor (2) tiende a ser el menos importante y lo analizaré brevemente después. El factor (3) es un tanto técnico para responderlo con total generalidad, por lo que lo analizaré al final.
El valor de la obra protegida por derechos de autor
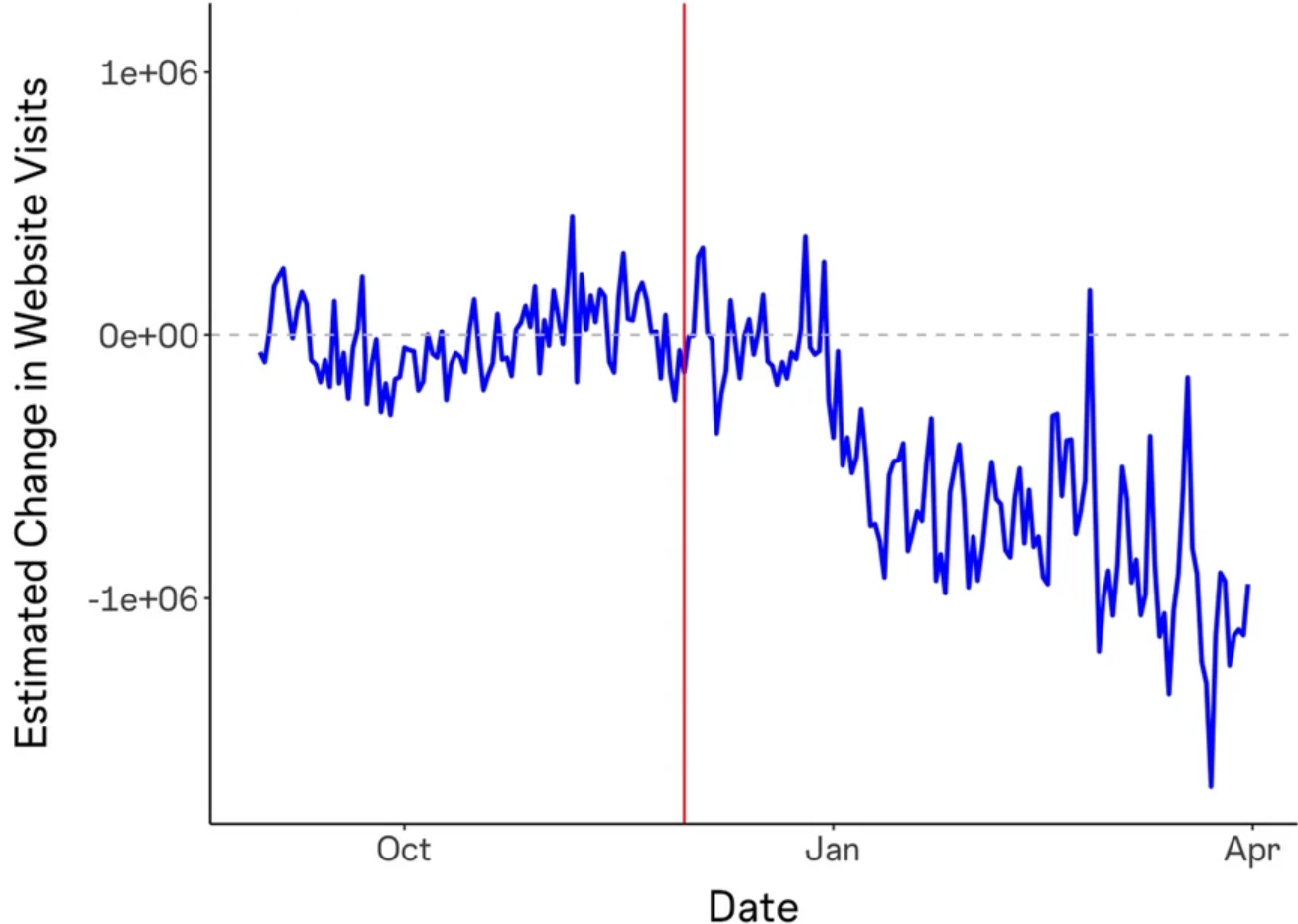
Los efectos sobre el valor de mercado de los datos de entrenamiento de ChatGPT van a variar mucho de una fuente a otra, y los datos de entrenamiento de ChatGPT no son de conocimiento público, por lo que no podemos responder a esta pregunta directamente. Sin embargo, algunos estudios han intentado cuantificar cómo podría ser esto plausiblemente. Por ejemplo, “ Las consecuencias de la IA generativa para las comunidades de conocimiento en línea ” descubrió que el tráfico a Stack Overflow disminuyó aproximadamente un 12 % después del lanzamiento de ChatGPT:
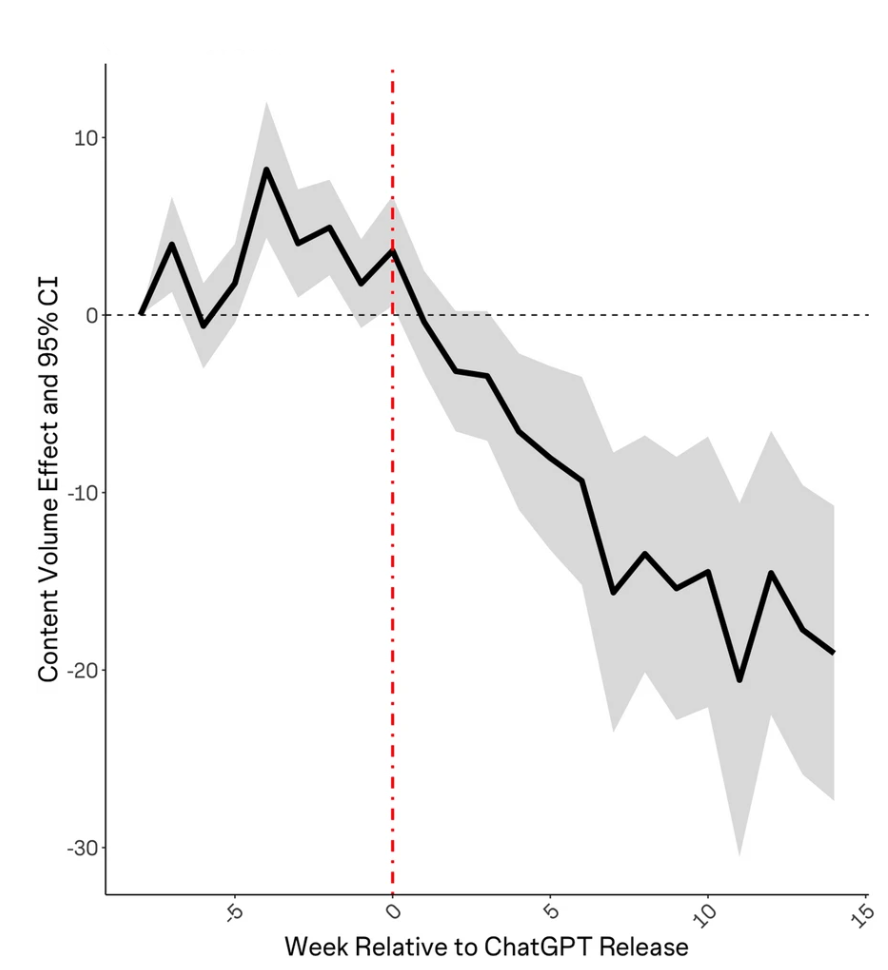
También encontraron una disminución en los volúmenes de publicación de preguntas por tema después del lanzamiento de ChatGPT:
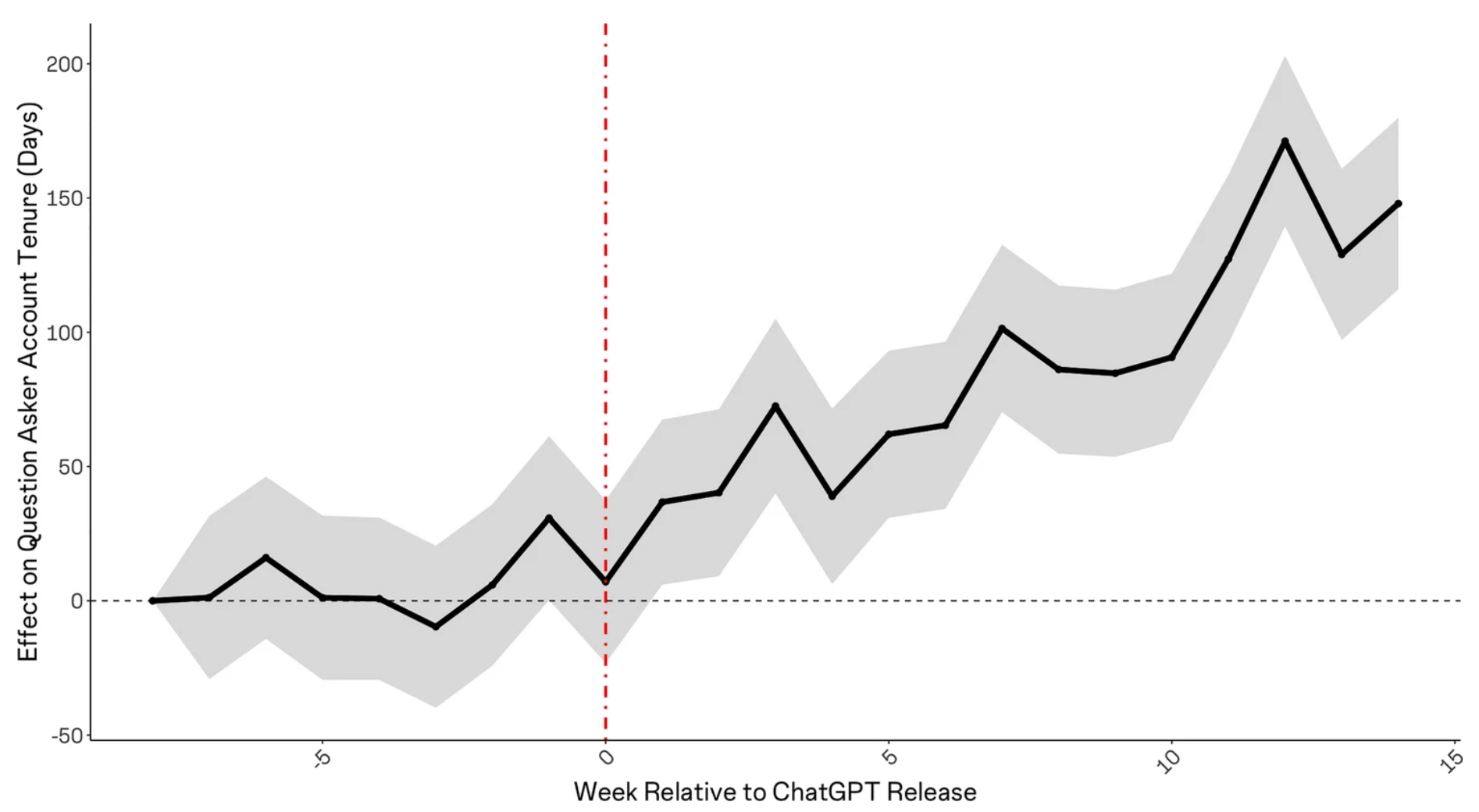
Y por último, descubrieron que la edad promedio de la cuenta de un autor de preguntas tiende a aumentar después del lanzamiento de ChatGPT, lo que sugiere que los miembros más nuevos no se unen o abandonan la comunidad:
ChatGPT
Estos efectos no van a ser universales (el mismo estudio no encontró descensos similares en la actividad del sitio web en Reddit), pero es poco probable que Stack Overflow sea el único sitio web afectado por el lanzamiento de ChatGPT. El sitio web de ayuda con las tareas escolares Chegg, por ejemplo, vio caer sus acciones un 40 % después de informar que ChatGPT estaba perjudicando su crecimiento. Esto no quiere decir que ChatGPT se haya entrenado en Stack Overflow o Chegg, o incluso que los efectos de mercado en Stack Overflow y Chegg sean algo malo, pero claramente puede haber efectos de mercado de ChatGPT en sus datos de entrenamiento.
El sistema informativo colapsará si la IA sigue robando contenido a los medios
Los desarrolladores de modelos como OpenAI y Google también han firmado muchos acuerdos de licencia de datos para entrenar sus modelos con datos protegidos por derechos de autor: por ejemplo, con Stack Overflow , Reddit , The Associated Press , News Corp , etc. No está claro por qué se firmarían estos acuerdos si el entrenamiento con estos datos fuera un «uso justo», pero ese no es el punto. Dada la existencia de un mercado de licencias de datos, el entrenamiento con datos protegidos por derechos de autor sin un acuerdo de licencia similar también es un tipo de daño al mercado, porque priva al titular de los derechos de autor de una fuente de ingresos.
Naturaleza comercial o para fines educativos sin fines de lucro
Tomar material de una obra protegida por derechos de autor y dañar su valor de mercado no siempre implica la descalificación del uso legítimo. Por ejemplo, un crítico de libros podría citar fragmentos de un libro en una crítica y, aunque su crítica podría dañar el valor de mercado del libro original, citarlo podría considerarse igualmente un uso legítimo. Esto se debe a que una crítica tiene un propósito diferente al del libro original y, por lo tanto, no lo sustituye ni compite con él en el mercado.
Esta distinción –entre usos sustitutivos y no sustitutivos– es en realidad el origen del “uso legítimo” a partir del caso Folsom v. Marsh de 1841 , en el que el acusado copió partes de una biografía de George Washington para hacer una versión propia. Allí se dictaminó que:
[Un] crítico puede citar de manera justa gran parte de la obra original, si su intención es realmente utilizar los pasajes con el propósito de hacer una crítica justa y razonable. Por otra parte, es igualmente claro que si cita las partes más importantes de la obra, no con el propósito de criticar, sino de sustituir el uso de la obra original y la reseña, tal uso será considerado, en derecho, como piratería.
Obras protegidas por derechos de autor
En muchos casos recientes, el factor (1) se ha considerado en términos de “capacidad de transformación”; por ejemplo, las conclusiones del Segundo Circuito en Authors Guild. v. Google sobre Google Books, según las cuales:
La digitalización no autorizada por parte de Google de obras protegidas por derechos de autor, la creación de una función de búsqueda y la visualización de fragmentos de esas obras son usos legítimos que no infringen los derechos de autor. El propósito de la copia es altamente transformador, la exhibición pública del texto es limitada y las revelaciones no proporcionan un sustituto comercial significativo para los aspectos protegidos de los originales.
La Corte Suprema ha aclarado la importancia de la “transformación” en el caso de 2023 Andy Warhol Foundation for the Visual Arts v. Goldsmith , señalando que solo debe considerarse “en la medida necesaria para determinar si el propósito del uso es distinto del original”, y que el primer factor es “una investigación objetiva sobre qué uso se hizo, es decir, qué hace el usuario con la obra original”. Señalan que “el primer factor se relaciona con el problema de la sustitución, la bestia negra del derecho de autor” y lo resumen de la siguiente manera:
Naturaleza comercial del uso
En resumen, el primer factor de uso justo tiene en cuenta si el uso de una obra protegida por derechos de autor tiene un propósito adicional o un carácter diferente, lo cual es una cuestión de grado, y el grado de diferencia debe sopesarse frente a la naturaleza comercial del uso. Si una obra original y un uso secundario comparten los mismos propósitos o propósitos muy similares, y el uso secundario es de naturaleza comercial, es probable que el primer factor influya en contra del uso justo, a menos que exista otra justificación para la copia.
ChatGPT es un producto comercial, por lo que una pregunta inicial podría ser: ¿ChatGPT tiene un propósito similar al de sus datos de entrenamiento?
En la práctica, resulta difícil razonar sobre el “propósito” de un producto tan amplio como ChatGPT, o el “propósito” de Internet en su totalidad. Una mejor explicación sería: ¿los daños al mercado que ChatGPT causa provienen de la producción de sustitutos que compiten con los originales? ¿O es un efecto indirecto, como el que podría tener un crítico de libros sobre un libro?
Daños al mercado causados por ChatGPT
Creo que es bastante obvio que los daños al mercado causados por ChatGPT provienen principalmente de la producción de sustitutos. Por ejemplo, si tuviéramos la pregunta de programación «¿Por qué 0,1 + 0,2 = 0,30000000000000004 en aritmética de punto flotante?», podríamos preguntarle a ChatGPT y recibir la respuesta de la izquierda, en lugar de buscar en Stack Overflow la respuesta de la derecha:
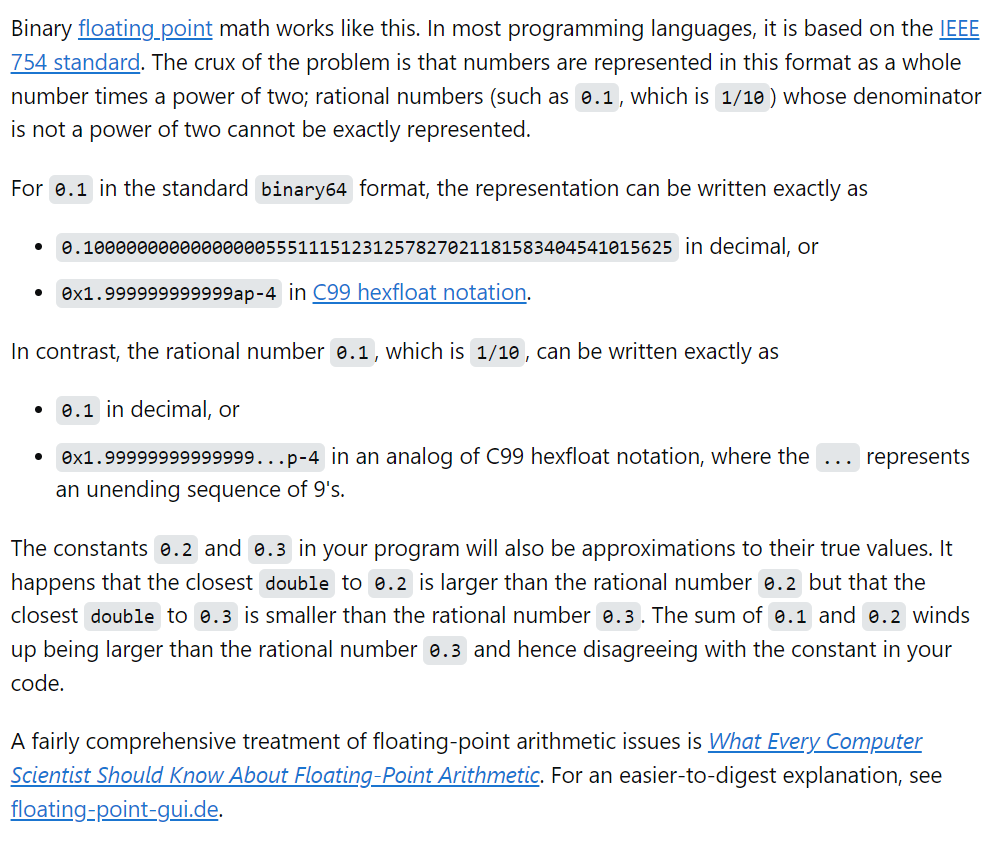 Disminución de tráfico en sitios web
Disminución de tráfico en sitios web
Estas respuestas no son muy similares, pero tienen el mismo propósito básico. Los daños al mercado que genera este tipo de uso se pueden medir en la disminución del tráfico del sitio web a Stack Overflow.
Este es un ejemplo de una sustitución exacta, pero en realidad la sustitución es una cuestión de grado. Por ejemplo, las respuestas existentes a todas las siguientes preguntas también responderían a nuestra pregunta original, dependiendo de cuánto pensamiento independiente estemos dispuestos a poner en ello:
- “¿Por qué 0,2 + 0,4 = 0,600000000000000008 en aritmética de punto flotante?”
- “¿Cómo se representan los decimales en punto flotante?”
- “¿Cómo funcionan los números de punto flotante?”
La naturaleza de la obra protegida por derechos de autor
La naturaleza de una obra protegida por derechos de autor (ya sea una obra creativa altamente protegida por derechos de autor o una obra factual levemente protegida por derechos de autor) varía mucho en Internet. Pero la mayoría de los datos en Internet están protegidos por derechos de autor en algún grado, por lo que es poco probable que el factor (2) apoye firmemente el «uso justo». En la práctica, este factor tiende a ser el menos importante de todos modos.
La cantidad y sustancialidad de la porción utilizada
Hay dos interpretaciones del factor (3):
- Los datos de entrada del modelo son copias completas de datos protegidos por derechos de autor, por lo que la “cantidad utilizada” es la totalidad de la obra protegida por derechos de autor. Esto podría perjudicar el “uso justo”.
- Los resultados del modelo casi nunca son copias de datos protegidos por derechos de autor, por lo que la “cantidad utilizada” es casi cero. Esto podría influir en el “uso justo”.
Pero la interpretación (2) no es del todo correcta, porque el propósito del copyright no es proteger las obras exactas producidas por un autor (de lo contrario, sería trivial evitarlo haciendo pequeños ajustes a una obra protegida por derechos de autor). Lo que el copyright realmente protege son las decisiones creativas que toma un autor. El arte del collage es un ejemplo simple de esta distinción: un artista de collage no obtendrá protección de derechos de autor por las obras subyacentes que utiliza, pero sí obtendrá protección de derechos de autor por las decisiones creativas que tomó al organizar esas obras.
Cada palabra de una novela es el resultado de una elección
De manera similar, aunque el autor de una novela típica no inventa palabras nuevas, sí obtiene protección de derechos de autor por las decisiones que toma al ordenar las palabras existentes. Cada palabra de una novela es el resultado de una elección (es decir, la selección de un resultado entre una serie de resultados posibles) y es la suma de todas estas elecciones lo que está protegido por los derechos de autor. Podemos estudiar estas elecciones cuantitativamente utilizando la teoría de la información.
La unidad de medida de una elección única es el bit de información, que representa una elección binaria. La cantidad promedio de información en una distribución es la entropía de esa distribución, medida en bits (Shannon fue el primero en estimar que la entropía de un texto inglés típico se encontraba aproximadamente entre 0,6 y 1,3 bits por carácter). La cantidad de información compartida entre dos distribuciones es su información mutua (IM), que se puede expresar como:
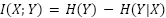 donde
donde 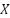 y
y 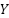 son variables aleatorias,
son variables aleatorias, 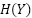 es la entropía marginal de , y
es la entropía marginal de , y 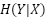 es la entropía condicional de dado . Si es una obra original, y es una transformación de ella, entonces la información mutua
es la entropía condicional de dado . Si es una obra original, y es una transformación de ella, entonces la información mutua 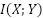 indica cuánta información de se tomó para crear . Para el factor (3) específicamente, nos interesa la información mutua relativa a la cantidad de información en la obra original. Podemos llamarla información mutua relativa (IRM) y definirla como:
indica cuánta información de se tomó para crear . Para el factor (3) específicamente, nos interesa la información mutua relativa a la cantidad de información en la obra original. Podemos llamarla información mutua relativa (IRM) y definirla como: 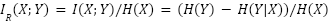
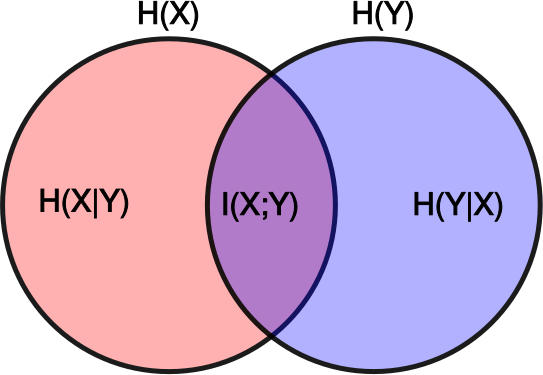
Área de la intersección relativa
Visualmente, si el círculo rojo de abajo representa la información presente en la obra original, y el círculo azul representa la información presente en la nueva obra, entonces la información mutua relativa será el área de la intersección relativa al área del círculo rojo:
En el contexto de la IA generativa, nos interesa el RMI, donde representa un posible conjunto de datos de entrenamiento y 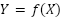 representa una colección de resultados del modelo, y
representa una colección de resultados del modelo, y 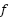 representa el proceso de entrenamiento y muestreo de un modelo generativo:
representa el proceso de entrenamiento y muestreo de un modelo generativo:
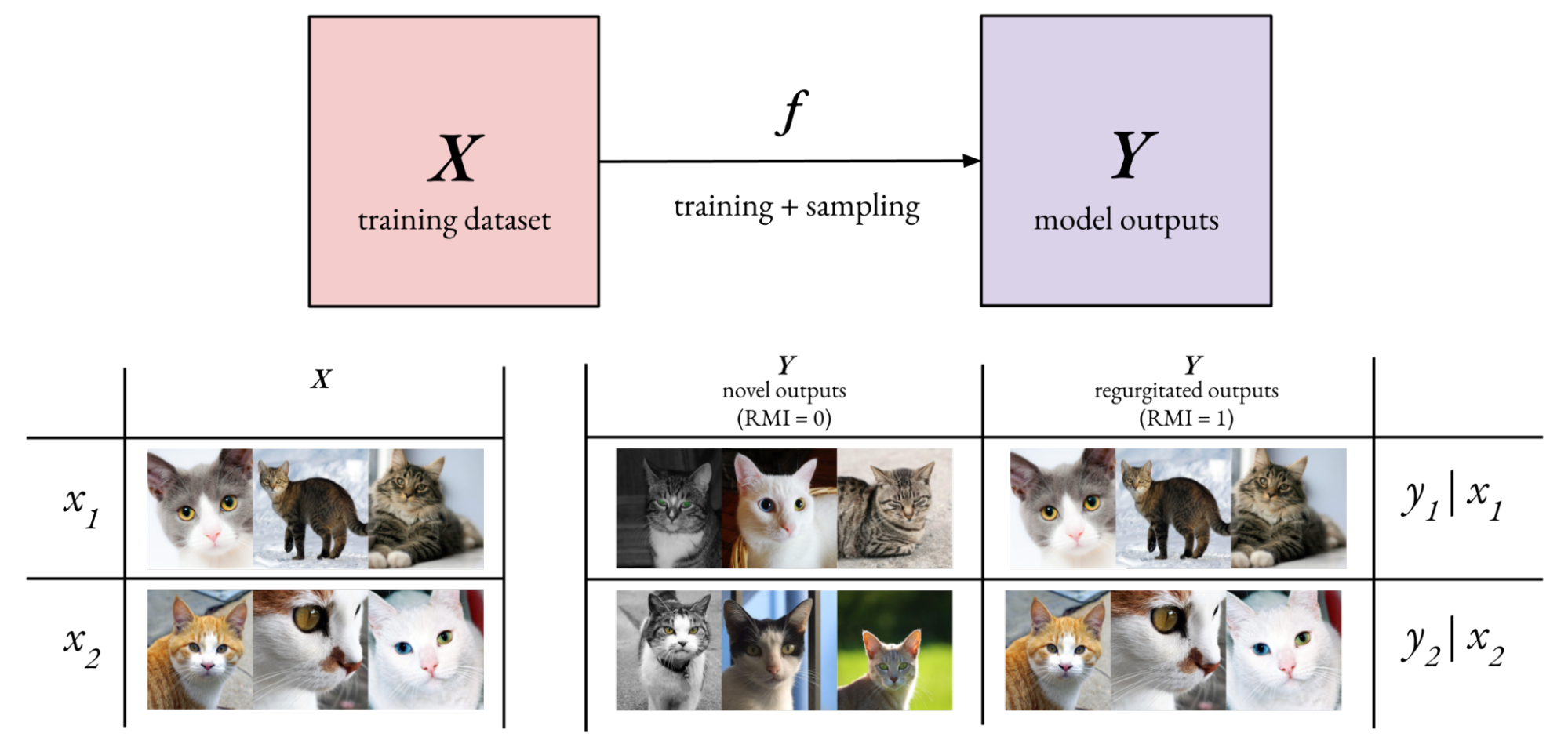
En la práctica, suele ser fácil estimar la entropía de los resultados de un modelo generativo entrenado. Sin embargo, estimar la entropía marginal de los resultados del modelo agregados a todos los conjuntos de datos de entrenamiento posibles será difícil. Estimar 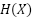 la entropía real de la distribución de entrenamiento es difícil, pero posible.
la entropía real de la distribución de entrenamiento es difícil, pero posible.
Modelos de baja entropía
Una suposición que podríamos hacer es que 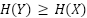 . Esto podría ser razonable de suponer, porque los modelos generativos que se ajustan perfectamente a su distribución de entrenamiento tendrán
. Esto podría ser razonable de suponer, porque los modelos generativos que se ajustan perfectamente a su distribución de entrenamiento tendrán 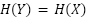 , al igual que los modelos generativos que se ajustan en exceso y memorizan sus puntos de datos. Los modelos generativos que se ajustan por debajo pueden introducir ruido adicional, lo que podría hacer que
, al igual que los modelos generativos que se ajustan en exceso y memorizan sus puntos de datos. Los modelos generativos que se ajustan por debajo pueden introducir ruido adicional, lo que podría hacer que 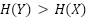 . Cuando , podemos limitar el RMI desde abajo como:
. Cuando , podemos limitar el RMI desde abajo como: 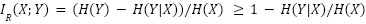
La intuición básica detrás de este límite es que es más probable que los resultados de modelos de baja entropía incluyan información de los datos de entrenamiento del modelo. En el caso extremo, este es el problema de la regurgitación, donde un modelo genera de manera determinista partes de sus datos de entrenamiento. Pero incluso las muestras no deterministas pueden usar información de los datos de entrenamiento hasta cierto punto: la información puede simplemente mezclarse en toda la muestra en lugar de copiarse directamente.
Reducir la entropía
Tenga en cuenta que no existe una razón fundamental por la que la entropía de los resultados de un modelo deba ser menor que la entropía real, pero en la práctica los desarrolladores de modelos tienden a elegir procedimientos de entrenamiento e implementación que favorecen los resultados de baja entropía. La razón básica de esto es que los resultados de alta entropía implican más aleatoriedad en su proceso de muestreo, lo que puede hacer que sean incoherentes o contengan alucinaciones.
A continuación, enumeraré algunos procedimientos de capacitación e implementación para reducir la entropía, aunque esta no es una lista exhaustiva:
Repetición de datos durante el entrenamiento
Es una práctica habitual mostrarle a un modelo un punto de datos en particular varias veces durante su proceso de entrenamiento. Esto no siempre es problemático, pero si se hace en exceso, el modelo acabará memorizando el punto de datos y lo repetirá en el momento de la implementación.
Podemos ver un ejemplo sencillo de esto al ajustar GPT-2 en un subconjunto de las obras de Shakespeare. Los colores que se muestran a continuación indican la entropía por token ; el texto rojo es más aleatorio y el texto verde es más determinista.

Después de que el modelo se entrena en cada punto de datos una vez, sus finalizaciones en el mensaje “Primer ciudadano:” son de alta entropía y novedosas, aunque incoherentes. Pero después de entrenar en cada punto de datos diez veces, termina memorizando el comienzo de la obra Coriolanus y regurgitándola cuando se le indica.
Con cinco repeticiones, el modelo hace algo entre la regurgitación y la generación creativa: algunas partes de su resultado son novedosas, otras se memorizan y las dos se mezclan en su resultado. Si la entropía real del texto en inglés fuera de alrededor de 0,95 bits por carácter, diríamos que alrededor 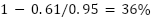 de estos resultados corresponden a la información del conjunto de datos de entrenamiento.
de estos resultados corresponden a la información del conjunto de datos de entrenamiento.
Aprendizaje por refuerzo
La razón principal por la que ChatGPT produce resultados de baja entropía es porque se “entrena posteriormente” mediante aprendizaje de refuerzo, en particular, aprendizaje de refuerzo a partir de retroalimentación humana (RLHF). El RLHF tiende a reducir la entropía del modelo porque uno de sus principales objetivos es reducir la tasa de alucinaciones, y las alucinaciones suelen estar causadas por la aleatoriedad en el proceso de muestreo. Un modelo con entropía cero podría fácilmente tener una tasa de alucinaciones de cero, aunque básicamente estaría actuando como una base de datos de recuperación sobre su conjunto de datos de entrenamiento en lugar de un modelo generativo.
A continuación se muestran algunos ejemplos de consultas a ChatGPT, junto con sus entropías por token:

Información protegida por derechos de autor
Si 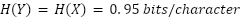 , estimamos que entre el 73 % y el 94 % de estos resultados corresponden a información en el conjunto de datos de entrenamiento. Esto podría ser una sobreestimación si RLHF hace
, estimamos que entre el 73 % y el 94 % de estos resultados corresponden a información en el conjunto de datos de entrenamiento. Esto podría ser una sobreestimación si RLHF hace 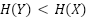 , pero aún hay una correlación empírica clara entre la entropía y la cantidad de información utilizada de los datos de entrenamiento. Por ejemplo, es fácil ver que los chistes producidos por ChatGPT se memorizan todos incluso sin conocer su conjunto de datos de entrenamiento, porque todos se producen de manera casi determinista.
, pero aún hay una correlación empírica clara entre la entropía y la cantidad de información utilizada de los datos de entrenamiento. Por ejemplo, es fácil ver que los chistes producidos por ChatGPT se memorizan todos incluso sin conocer su conjunto de datos de entrenamiento, porque todos se producen de manera casi determinista.
Este es un análisis bastante aproximado de cuánta información protegida por derechos de autor del conjunto de datos de entrenamiento llega a los resultados de un modelo, y una cuantificación exacta de la misma es una pregunta de investigación abierta. Pero lo más importante es que no es trivial, por lo que incluso la interpretación más generosa del factor (3) no respaldaría claramente el uso legítimo.
Uso justo
Ninguno de los cuatro factores parece influir a favor de que ChatGPT sea un uso justo de sus datos de entrenamiento. Dicho esto, ninguno de los argumentos aquí expuestos es fundamentalmente específico de ChatGPT, y se podrían plantear argumentos similares para muchos productos de IA generativa en una amplia variedad de dominios.